Dans cet article nous expliquons le fonctionnement de la convolution et de la convolution transposée. Comme ces opérations sont omniprésents dans les réseaux neurones, notamment dans la vision par ordinateur (computer vision), il est important de bien les comprendre pour connaître leur influence sur la structure du réseau. Ainsi l’objectif est de donner une définition à la fois rigoureuse et naturelle de ces opérations.
L’opération de convolution (et sa transposée) est divisée en deux familles : la convolution 1D et la convolution 2D. La famille dépend du format du tenseur en entrée :
- 1D : si c’est un tenseur à une dimension, avec éventuellement des composantes channels. Par exemple les séries temporelles qui sont des tenseurs de format [timestep, channels].
- 2D : si c’est un tenseur à deux dimensions, toujours avec éventuellement des composantes channels. Par exemple les images qui sont des tenseurs de format [width, height, channels]
La convolution 1D est très peu utilisée, à cause du fait que les cellules récurrentes (dont on parle dans cet article) traitent les séries temporelles plus efficacement que la convolution. Cependant nous commencerons par traiter le cas 1D en profondeur . En effet le cas 1D et le cas 2D fonctionnent sur le même principe, et le cas 2D s’en déduit aisément du cas 1D en répétant le principe sur les deux directions.
Il y a un certain nombres de paramètres pour définir une convolution.
Dans cet artcle, nous nous baserons sur la terminologie de keras.
Ainsi nous expliquerons le rôle des paramètres suivants lors l’instanciation d’un
keras.
- filters.
- kernel_size.
- strides.
- dilation_rate.
- use_bias.
Convolution 1D
Principe de base de la convolution
D’abords nous commençons par le cas plus simple possible, à savoir pas de composante channels, pas de biais et les paramètres strides et dilation_rate sont les valeurs par défaut.
Il y a plusieurs manières (équivalentes) de définir une convolution. Ici la manière la plus simple et la plus facile à étendre dans le cas tranposé est de la définir par sa matrice en tant qu’application linéaire entre vecteurs.
Plus formellement la définition est la suivante : soit  un entier, appelé kernel_size
et
un entier, appelé kernel_size
et ![K = [k_0,k_1, \dots, k_{n-1}]](https://www.augustehoangduc.fr/wp-content/ql-cache/quicklatex.com-57a73634543154dce45f09a9848a89a3_l3.png "Rendered by QuickLaTeX.com") un vecteur de nombres de taille , appelé kernel (son noyau).
Alors la convolution associée de kernel
un vecteur de nombres de taille , appelé kernel (son noyau).
Alors la convolution associée de kernel  appliquée sur un vecteur est la multiplication par la matrice suivante, où le nombre de colonnes est la taille du vecteur d’entrée :
appliquée sur un vecteur est la multiplication par la matrice suivante, où le nombre de colonnes est la taille du vecteur d’entrée :
![\[\begin{bmatrix} k_0 & k_1 & \cdots & k_{n-1}& 0 & \cdots & \cdots & \cdots & \cdots & 0 \\ 0 & k_0 & k_1 & \cdots & k_{n-1}& 0 & & & & \vdots \\ \vdots & 0 & k_0 & k_1 & \cdots & k_{n-1}& 0 & & & \vdots \\ \vdots & & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots & & \vdots \\ \vdots & & & \ddots & \ddots & \ddots & \ddots & \ddots & 0 & \vdots \\ \vdots & & & & 0 & k_0 & k_1 & \cdots & k_{n-1}& 0 \\ 0 & \cdots & \cdots & \cdots & \cdots & 0 & k_0 & k_1 & \cdots & k_{n-1}\\ \end{bmatrix}\]](https://www.augustehoangduc.fr/wp-content/ql-cache/quicklatex.com-5b46208027b0183e542e1893c718d732_l3.png "Rendered by QuickLaTeX.com")
Sur cette représentation on voit que chaque ligne est formée du vecteur kernel complété des 0, et sa position est décalée de une unité à chaque fois.
Autrement dit si  est un vecteur colonne de composante
est un vecteur colonne de composante  ,
alors son image par la convolution est le vecteur colonne
,
alors son image par la convolution est le vecteur colonne  de composantes :
de composantes :

La taille du vecteur est égale au nombre de fois que l’on peut déplacer le kernel.
Ici c’est donc  , mais il n’est pas important de retenir cette formule.
, mais il n’est pas important de retenir cette formule.
Il faut interpréter cette représentation par le fait que kernel agit comme une fenêtre qui glisse sur l’entrée .
L’animation suivante illustre cette interprétation lorsque kernel est de taille 3, l’entrée est de taille  (et la sortie est de taille
(et la sortie est de taille  ).
).
Ajout d’un biais
De la même manière qu’un keras.
Ajout d’un stride
Dans la version de base de la convolution, à chaque étape le kernel est déplacé de un cran.
Ce nombre de cran s’appelle stride (traduit par foulée ou enjambée).
Ainsi la version de base s’effectue un stride égale à 1.
De manière générale si stride vaut  , alors à chaque itération le kernel est décalé de crans.
, alors à chaque itération le kernel est décalé de crans.
L’animation suivante illustre la convolution avec un stride égale à 2 et avec l’utilisation d’un biais.
Ajout d’un dilation_rate
Dans la version de base de la convolution, le kernel est multiplié par des valeurs de l’entrée qui sont consécutifs.
Le dilation_rate (traduit par taux de dilatation) permet d’indiquer que l’on veut multiplier le kernel par des valeurs espacées.
Par conséquent si le dilation rate vaut  , alors le kernel sera multiplié par des valeurs de l’entrée qui seront espacées de crans.
, alors le kernel sera multiplié par des valeurs de l’entrée qui seront espacées de crans.
L’animation suivante illustre la convolution avec un dilation rate à 2 et l’utilisation d’un biais.
Ajout d’une dimension channel
Mettons nous maintenant dans le cas où l’entrée est un tenseur de format [timestep, channels] avec channels de dimension  et
et la sortie de format [timestep, channels] avec channels de dimension
et
et la sortie de format [timestep, channels] avec channels de dimension  .
Alors tout se passe de la même manière que précédemment en remplaçant tous les nombres par des matrices que format adéquat.
.
Alors tout se passe de la même manière que précédemment en remplaçant tous les nombres par des matrices que format adéquat.
Plus formellement, l’entrée est du type  ,
,  ,
,  ,
,  avec
avec  un vecteur de taille (pour tout
un vecteur de taille (pour tout  ),
la sortie est de type
),
la sortie est de type  ,
,  ,
,  , avec
, avec  un vecteur de taille (pour tout )
et le kernel est de type
un vecteur de taille (pour tout )
et le kernel est de type  ,
,  ,
,  , avec une matrice de format
, avec une matrice de format  ,
,  (si par convention on multiplie les à gauche des
(si par convention on multiplie les à gauche des  )
)
L’animation suivante illustre la convolution avec  et
et  .
Noter que la dimension de sortie est déterminée par le paramètre filters.
.
Noter que la dimension de sortie est déterminée par le paramètre filters.
En résumé
Le schémas suivant résume des effets de strides et dilation_rate sur la matrice de la convolution et généralise la Figure 1.

Convolution 1D Transposée
Principe de base de la convolution transposée
De la même manière qu’on a défini la convolution par sa matrice en tant qu’application linéaire, nous allons définir la convolution transposée par sa matrice. Vous connaissez certainement la notion de matrice transposée. Eh bien tout simplement, la matrice de la convolution transposée est la transposée de la matrice de la convolution. D’où l’intérêt d’avoir choisi cette définition.
Plus formellement dans le cas le plus simple, la définition est la suivante :
soit un entier (le kernel_size) et un vecteur de nombres de taille (le kernel).
Alors la convolution transposée de kernel appliquée sur un vecteur est la multiplication par la matrice suivante,
où le nombre de colonne est égal à la taille du vecteur d’entrée :
![\[\begin{bmatrix} k_0 & 0 & 0 & \cdots & \cdots & \cdots & 0 \\ k_1 & k_0 & 0 & & & & \vdots \\ \vdots & k_1 & k_0 & \ddots & & & \vdots \\ k_{n-1}& \vdots & k_1 & \ddots & \ddots & & \vdots \\ 0 & k_{n-1}& \vdots & \ddots & \ddots & 0 & \vdots \\ \vdots & \ddots & k_{n-1}& \ddots & \ddots & k_0 & 0 \\ \vdots & & \ddots & \ddots & \ddots & k_1 & k_0 \\ \vdots & & & \ddots & \ddots & \vdots & k_1 \\ \vdots & & & & \ddots & k_{n-1}& \vdots \\ 0 & \cdots & \cdots & \cdots & \cdots & 0 & k_{n-1}\\ \end{bmatrix}\]](https://www.augustehoangduc.fr/wp-content/ql-cache/quicklatex.com-6a30424de2cd157f1a6d7183ae3e24b6_l3.png "Rendered by QuickLaTeX.com")
Voici comment interpréter cette représentation.
On initialise la sortie à 0.
Ensuite on prend le premier coefficient du vecteur d’entrée et on le multiplie termes-à-termes avec le kernel.
On obtient alors un vecteur de taille que l’on ajoute termes-à-termes avec les premières valeurs de la sortie.
Enfin on répète l’opération d’un cran en entré et en sortie.
L’animation suivante illustre cette opération. Remarquer que la différence majeure avec la convolution est que le kernel glisse en face de la sortieb> et non pas en face de l’entrée.
Ajout du biais, strides et dilations_rate
Toutes ces notions s’en déduisent de la convolution en transposant. La figure suivante généralise la matrice de la figure Fig. 3 en illustrant l’effet du strides et de dilation rate.

L’animation suivante montre différents exemples de convolutions transposées avec différents strides et dilation rate.
Lien entre la convolution transposéet le Upsampling
Que se passe-t-il si on fait une convolution tranposée de stride=2, dilation_rate=1, avec un kernel de taille 2 égale à  ?
Si vous avez bien suivi, alors vous aurez compris que cette convolution transposée transforme un vecteur , , ,
?
Si vous avez bien suivi, alors vous aurez compris que cette convolution transposée transforme un vecteur , , ,  ,
,  ,
,  en le vecteur :
en le vecteur :

C’est donc équivalent à faire un upsampling de taille 2, c’est-à-dire multiplier par 2 la taille vecteur en recopiant en double les coefficients. Ainsi lorsque stride est supérieur à 2, on peut voir la convolution transposée comme une généralisation de l’opération upsampling avec des poids entraînables.
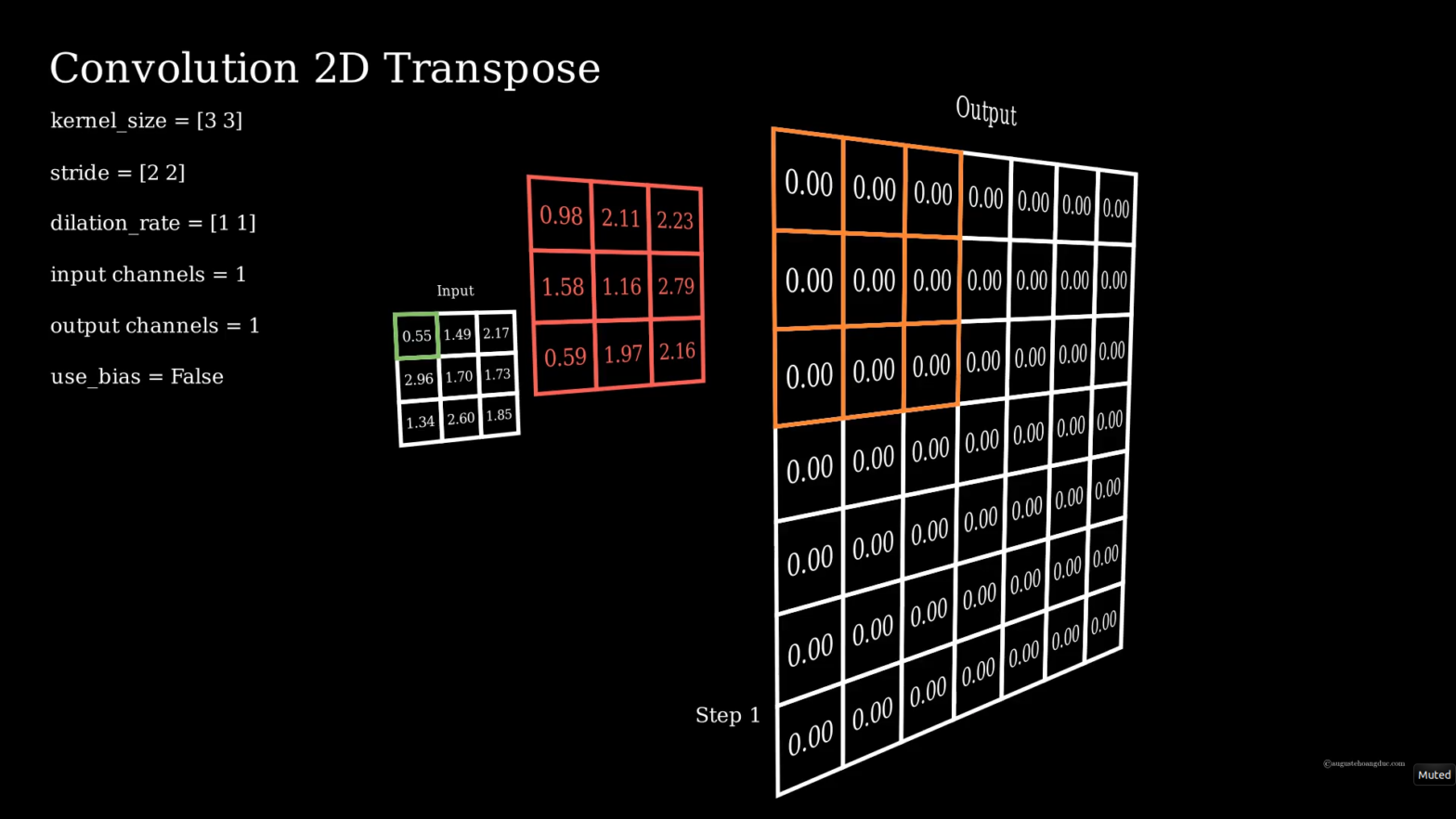
Convolution en dimension 2
La Convolution 2D et sa version transposé s’en déduisent naturellement en répétant les opérations sur les deux axes. En l’occurrence, le kernel est de dimension 2 et il faut le faire glisser dans les deux directions. De même strides et dilation_rate sont chacun une paire d’entiers (une valeur pour chaque direction).
Les deux animations suivantes illustrent plusieurs de convolutions et sa tranposée avec différents paramètres.
Conclusion
La convolution est facile à appréhender pour la plupart des gens, mais la convolution transposée est souvent mal comprise. Ce qu’il faut retenir c’est qu’avec une approche par sa matrice, sa définition devient très naturelle. Un autre chose à retenir est que la convolution transposée de stride supérieur à 2 a pour effet de faire un sur-échantillonnage (upsampling).